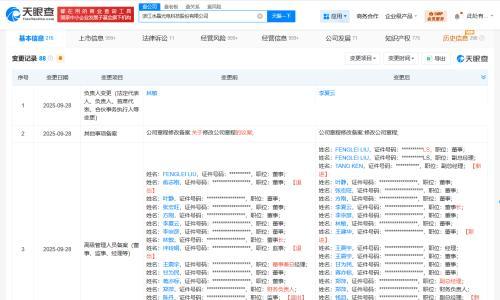
2025-05-22 12:33
近日,科技媒体marktechpost报道,Meta公司发布了J1系列模型,该模型通过强化学习和合成数据训练,在判断准确性和公平性方面取得突破性进展。J1系列模型旨在解决“LLM-as-a-Judge”模式中的一致性差、推理深度不足等问题。
传统奖励模型依赖静态标注,难以有效评估主观或开放性问题。而J1采用22000个合成偏好对进行训练,结合Group Relative Policy Optimization(GRPO)算法,优化训练过程并消除位置偏见。测试结果显示,J1-Llama-70B在PPE基准测试中准确率达69.6%,远超同类模型。此外,J1支持多种判断格式,展现出高度灵活性和通用性。这一成果表明,推理质量而非单纯的数据量,是判断模型性能的关键因素。




 扫一扫关注微信
扫一扫关注微信