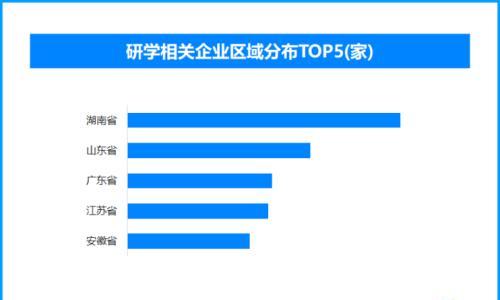
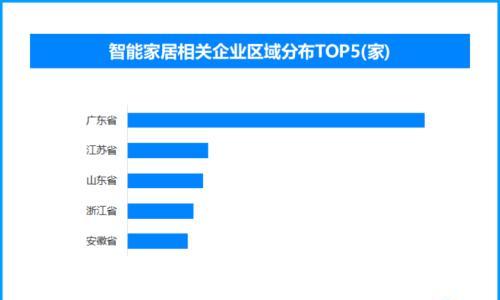
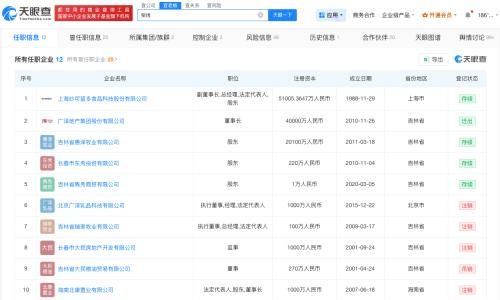
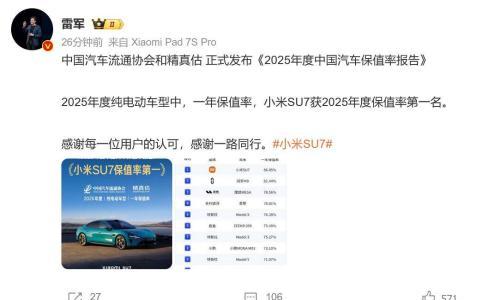
2026-01-30 08:53
2026年1月29日,SentinelOne与Censys联合研究显示,脱离主流平台防护、在本地运行的开源大语言模型易遭黑客劫持。研究历时293天,发现数千个公开Ollama部署实例中,约25%可被读取系统提示词,其中7.5%提示词支持有害行为。攻击者可操控模型生成钓鱼内容、虚假信息、仇恨言论甚至儿童性虐待材料。Meta Llama、Google Gemma等主流模型衍生版本成主要目标。专家指出,模型发布方需承担注意义务,提供风险记录与缓解工具。
免责声明:本文内容由开放的智能模型自动生成,仅供参考。






 扫一扫关注微信
扫一扫关注微信