2026-01-26 10:53
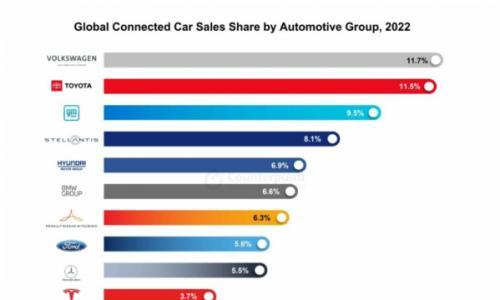
1月24日,训练数据公司Mercor发布研究报告称,主流AI模型在真实办公场景多步骤任务中准确率最高仅24%。研究采用新基准APEX-Agents,模拟律师、顾问等职业工作流,要求跨邮件、PDF、表格等多源信息协同处理。Gemini 3 Flash与GPT-5.2分列前两位,但均未超25%;多数模型低于20%。Mercor CEO指出,AI因上下文整合能力薄弱,易混淆或放弃任务,目前仅堪比“不可靠实习生”。相较一年前5%-10%的水平,准确率已显著提升,但距胜任复杂知识工作仍有明显差距。
免责声明:本文内容由开放的智能模型自动生成,仅供参考。










 扫一扫关注微信
扫一扫关注微信