2025-07-22 12:40
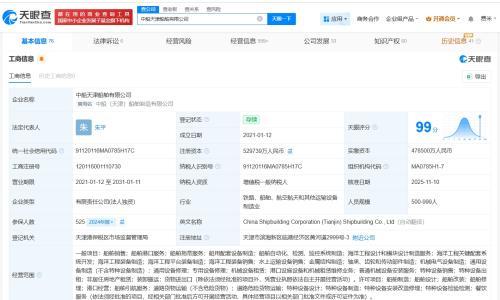
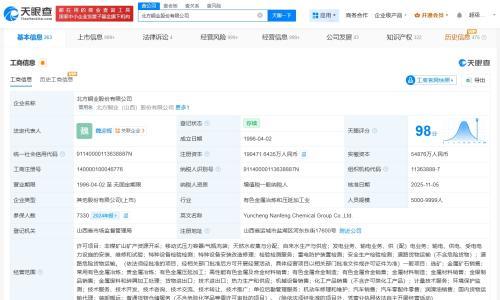
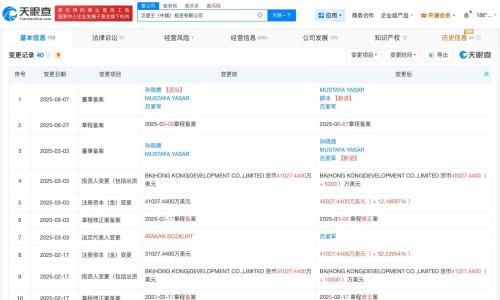
字节跳动Seed团队发布全新Vision-Language-Action模型GR-3,该模型具备理解抽象语言指令、精细操作柔性物体的能力,并可高效泛化至新物体与新环境。与以往模型不同,GR-3仅需少量人类数据即可完成微调,显著降低训练成本。
GR-3通过融合遥操作机器人数据、VR人类轨迹数据及大规模视觉语言数据进行联合训练,提升任务处理能力。配合专为其打造的双臂移动机器人ByteMini,GR-3可在狭小空间完成高精度操作。
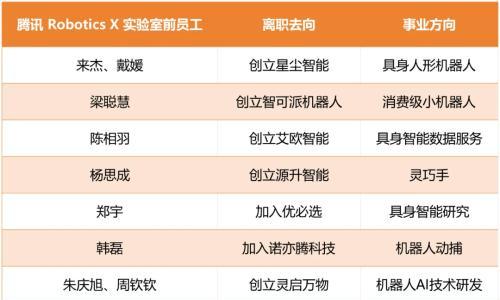
实验表明,GR-3在多步指令执行、衣物整理、新物体抓取等任务中表现优异,成功率显著提升,展现通用机器人“大脑”的潜力。


 扫一扫关注微信
扫一扫关注微信