2025-03-24 11:09
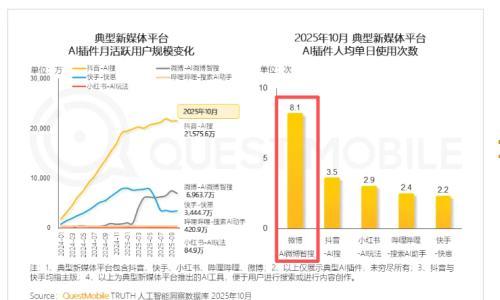
Meta AI与加州大学伯克利分校近日联合推出了一款名为SWEET-RL的强化学习框架,并发布了CollaborativeAgentBench(ColBench)基准测试。这一创新旨在提升大语言模型(LLMs)在多轮人机协作任务中的表现,特别是在后端编程和前端设计领域。
SWEET-RL通过逐轮优化决策,显著提高了模型的任务完成率。其采用非对称的“演员-评论家”结构,评论家可访问额外信息以精确评估演员决策,从而简化信用分配过程。实验结果显示,SWEET-RL在后端编程任务中通过率提升至48.0%,前端设计任务的余弦相似度达到76.9%。
ColBench基准测试包含超过10000个训练任务和1000个测试案例,模拟真实的人机协作场景,为多轮任务提供了可靠的评估标准。





 扫一扫关注微信
扫一扫关注微信